
Introduction
Most companies are sitting on a goldmine of sales data, call recordings, CRM histories, win/loss notes, and deal patterns, yet their AI tools don't actually know any of it. That gap has a real cost: poor data quality runs the average B2B company $12.9 to $15 million per year, and 76% of CRM admins report that less than half their organization's CRM data is accurate.
This guide covers what "training AI on sales data" actually means in practice: what data you need, the exact steps to follow, and what separates useful AI from expensive noise. Whether you lead sales enablement, manage channel partners, or own revenue operations, connecting your proprietary sales knowledge to AI will determine whether your investment delivers real coaching results or just collects dust.
Key Takeaways
- Training AI on sales data means connecting your CRM records, call transcripts, and win/loss history to an existing AI model, no data science team required
- RAG (Retrieval Augmented Generation) is the practical approach for most teams, it layers your sales knowledge onto existing foundation models without heavy technical lift
- Data quality outperforms data volume, clean, structured, consistently labeled records deliver better results than massive piles of inconsistent data
- The biggest ROI comes from AI embedded directly in workflows: coaching, forecasting, and partner enablement, not isolated tools sitting outside your process
- Most failures trace back to skipping data preparation or deploying AI without feedback loops to keep it accurate
What "Training AI on Sales Data" Really Means
Training AI does not require building a model from scratch. For most sales organizations, it means customizing an existing foundation model like GPT-4 with your proprietary sales knowledge so it can answer context-specific questions, coach reps on your product, and analyze patterns in your deals. Three approaches make this possible, each with different costs, complexity, and use cases.
Three Approaches to Training AI on Sales Data
RAG (Retrieval Augmented Generation):
- Indexes your sales documents, call transcripts, and CRM data in a vector database
- AI retrieves relevant information at query time to answer questions
- Best for sales knowledge bases, real-time coaching, and Q&A on products or playbooks
- Stays current through live data retrieval, unlike fine-tuning, which freezes knowledge at the point of training
- Low update costs, simply refresh the knowledge base without retraining
Fine-Tuning:
- Retrains a model's parameters on curated examples of your sales conversations and objection handling
- More resource-intensive but teaches voice, style, and recurring decision logic
- Costs $50K–$500K per training run for large models
- Knowledge becomes static until next retraining cycle
- Better for behavioral coaching and style consistency
Pre-Built AI Sales Platforms:
- Purpose-built tools already architected to ingest call data, CRM records, and training content
- Remove the need to build data pipelines from scratch
- Purchasing from specialized vendors succeeds 67% of the time, while internal builds succeed only one-third as often
- Platforms like Pifini handle ingestion and indexing automatically for partner and sales enablement
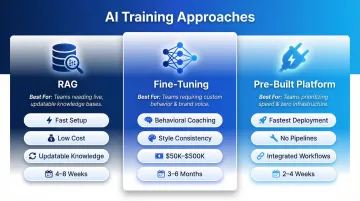
For most sales leaders, the right path is either RAG-based customization or a purpose-built sales AI platform, not full model retraining.
What Sales Data You Need and How to Prepare It
Core Sales Data Types That Generate AI Value
CRM Deal Records:
- Stage history and progression
- Close rates and win/loss outcomes
- Deal size and firmographics
- Note: 40% of CRM data becomes obsolete annually through job changes and company transformations
Sales Call Recordings and Transcripts:
- Sellers who use AI to optimize their activities increase win rates by 50%
- Must be tagged by deal stage, objection type, and outcome
- Transcripts provide more training value than raw audio
Win/Loss Notes and Opportunity Summaries:
- Structured feedback on why deals closed or were lost
- Competitive intelligence and objection patterns
- Most valuable when following standardized format
Product and Pricing Documentation:
- Enables AI to answer product-specific questions
- Should include feature specifications, use cases, and pricing tiers
- Keep updated as product evolves
Sales Playbooks and Objection-Handling Guides:
- Your proven methodologies and messaging frameworks
- Objection responses from top performers
- Discovery question frameworks
Partner and Channel Sales Data:
- Reseller performance metrics and MDF usage records
- Certification and training completion history
This data type is especially critical for organizations with indirect sales motions, without it, AI recommendations won't reflect how channel partners actually sell.
Data Readiness Requirements
Collecting the right data types is only half the job. Before AI can use your data effectively, each source needs to meet basic quality standards:
- Consistent field naming: Standardize CRM stage names, objection categories, and outcome labels across all systems. 65% of teams report missing data, 53% report duplicates, and 68% report incomplete records, any of these will degrade model output.
- Sufficient, structured volume: RAG retrieval accuracy drops from 85–92% with governed data to 45–60% with ungoverned data. Five hundred well-structured call transcripts will outperform 5,000 untagged recordings.
- Deduplication and gap-filling: Remove duplicate or incomplete records and fill critical missing fields. Sales reps already waste 550 hours per year on bad data, feeding that same data to AI compounds the problem.
- PII anonymization: Redact sensitive customer information before any external processing, and confirm compliance with GDPR or applicable regional privacy requirements.
Data Structuring: The Step Most Guides Skip
Sales data must be chunked, labeled, and indexed before it becomes useful for AI retrieval.
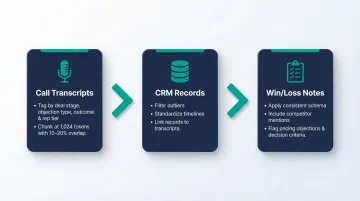
Call transcripts need the most attention. Tag each transcript by deal stage, objection type, outcome, and rep performance tier so the model can identify what separates top performers from average ones. For chunking, a size of 1,024 tokens balances response time and quality, with 10–20% overlap between chunks to preserve context continuity.
CRM records require filtering before indexing. Remove outlier deals that skew stage-progression patterns, standardize timeline formats, and link deal records to their corresponding call transcripts wherever possible.
Win/loss notes only deliver value when they follow a consistent schema. Every entry should include competitor mentions, pricing objections, and decision criteria, with outcome labels that are unambiguous and applied uniformly.
The model you choose matters less than the data you feed it. Poorly structured inputs produce confident-sounding but inaccurate outputs, a problem that's harder to diagnose after deployment than before it.
How to Train AI on Your Company's Sales Data: Step-by-Step
Step 1: Define the Sales Problem You're Solving
Identify the single highest-friction use case before touching any data:
- Accelerating rep ramp time
- Improving forecast accuracy
- Automating call scoring
- Enabling partner knowledge
95% of organizations deploying generative AI saw zero measurable return, and 50% of projects were abandoned after proof of concept due to unclear business value. Unfocused AI projects spread across multiple goals fail at the same rate as projects with no goal at all.
The fix is simple: anchor the project to one measurable outcome before you select a single data source.
Define the Success Metric Upfront:
- Time-to-first-deal for new reps
- Forecast variance reduction
- Call quality scores improvement
- Partner certification completion rates
This metric governs which data to prioritize and how to measure AI effectiveness.
Step 2: Audit, Clean, and Structure Your Sales Data
Conduct a Data Audit:
- Review CRM, call intelligence tools, LMS, and partner portals
- Flag data gaps (e.g., missing stage transition dates)
- Identify inconsistencies (e.g., different reps labeling the same objection differently)
- Assess privacy risks (e.g., customer PII in free-text fields)
Poor data at this stage is the single most common cause of AI systems that confidently produce wrong answers.
Apply Data Hygiene Standards:
- Standardize field formats across all systems
- Remove duplicate records
- Establish minimum completeness thresholds per record type
- Document which data categories are approved for AI training versus restricted
- Confirm data governance and security standards before connecting any external AI platform
Step 3: Choose and Configure Your AI Training Approach
Select the approach matching your technical capacity and urgency:
| Approach | Best For | Setup Time | Technical Skill Required |
|---|---|---|---|
| RAG | Knowledge retrieval, Q&A, coaching | 4–8 weeks | Low to moderate |
| Fine-tuning | Behavioral coaching, style training | 3–6 months | High |
| Pre-built platform | Fast deployment, integrated workflows | 2–4 weeks | Low |
Configuration Steps:
- Link your CRM (Salesforce, HubSpot)
- Connect call intelligence tools
- Integrate content repositories
- For manual RAG builds: establish a chunking strategy, embedding model, and vector database
- Pifini handles ingestion and indexing automatically across CRM, call intelligence, and LMS sources, no custom data pipelines required
Step 4: Deploy, Validate, and Build a Feedback Loop
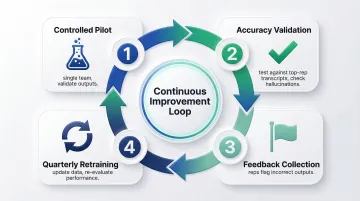
Run a Controlled Pilot:
- Start with a single team or use case
- Validate AI outputs against verified, high-quality responses
- Test objection-handling responses against your best-performing rep's call transcripts
- Check for accuracy gaps or hallucinations
Establish Continuous Feedback:
- Create a process for reps or managers to flag incorrect AI outputs
- Update training data when your product or playbook changes
- Re-evaluate AI performance quarterly, models trained on sales data typically degrade within 6–12 months without active retraining
Over 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs and unclear value. A structured feedback loop, tied to your original success metric, is what separates the projects that survive from those that stall.
Key Variables That Determine Results
Outcomes from AI trained on sales data vary significantly based on four controllable variables, even when two teams use the same underlying model.
Data Quality vs. Data Volume
AI outputs are a direct function of input quality. Multiple studies consistently show that a small number of high-quality, diverse examples outperforms larger, noisier datasets. A model trained on 500 well-structured, outcome-labeled call transcripts will outperform one trained on 5,000 untagged recordings.
The failure mode here is subtle: low-quality data produces confident but wrong answers. In sales, where reps act on AI-generated coaching or forecasts, that's costly. 84% of data and analytics leaders agree AI's outputs are only as good as its data inputs.
Feedback Loop Cadence
Sales data has a shelf life, products change, markets shift, and competitor messaging evolves. AI trained once and never updated becomes a liability as its knowledge drifts from current reality.
Teams that build quarterly retraining cycles and real-time flagging workflows maintain accuracy over time. Those that deploy and forget see adoption collapse within 6 months as reps stop trusting outputs. That pattern shows up in the data: the share of companies abandoning most of their AI initiatives before reaching production surged from 17% to 42% year over year.
Alignment Between AI Output and Sales Workflow
If reps have to leave their existing tools to access AI insights, they won't. Integration into CRM, call tools, or the LMS determines adoption rates more than any feature of the AI itself.
The utilization gap makes this concrete: sellers who effectively use AI are 3.7 times more likely to meet quota, yet 78% of B2B organizations have adopted AI for sales while fewer than half fully use those tools. That gap between adoption and utilization is almost always a workflow integration problem, not a technology problem.
Scope Specificity at Deployment
AI deployed to solve a narrow, well-defined problem, for example, "score inbound calls against our top 10 objection patterns", outperforms AI deployed to "improve sales performance" broadly. The training data, success metrics, and feedback loops are all aligned to one clear task.
Broad scope produces the opposite: scattered training data, unclear accuracy benchmarks, and no clear owner for maintaining the system. The 5% of organizations that generate measurable AI impact define specific workflow changes and measurable outcomes, rather than aspirational goals about what AI might accomplish.
Common Mistakes to Avoid When Training AI on Sales Data
Skipping the Data Preparation Phase
Feeding raw CRM exports or unedited call recordings directly into an AI system is the fastest way to produce unreliable results. Without preparation, 40–60% of raw sales data is unusable, and a 2024 CRM data survey found 65% of users report missing data, 53% report duplicates, and 68% report incomplete records.
Treat data preparation as the majority of the project, not a preliminary step. Budget 60–70% of your project time for auditing, cleaning, structuring, and labeling before any AI training begins.
Choosing the Wrong AI Approach for the Use Case
Teams often reach for fine-tuning when RAG would deliver results faster and at a fraction of the cost, or expect a pre-built platform to behave like a custom-tuned model without additional configuration. Match the approach to the actual use case:
- RAG for factual Q&A, product documentation retrieval, objection handling lookup
- Fine-tuning for teaching specific tone, voice, or behavioral patterns
- Pre-built platforms for integrated workflows that connect coaching, call scoring, and training without building infrastructure
Deploying AI Without Sales Rep Buy-In or Workflow Integration
A technically functional system that no one opens is a failed project. Misaligned incentives and absent end-user co-design kill more AI projects than bad models ever will. Adoption, not architecture, is where most initiatives collapse. To avoid it:
- Involve sales managers and top performers in the pilot phase
- Deploy within existing tools rather than asking reps to adopt a new interface
- Measure adoption rates alongside performance metrics
- Address "what's in it for me" explicitly in rollout communications
The payoff is real when adoption happens: 56% of sales professionals now use AI daily, and those users are twice as likely to exceed their targets. That outcome depends entirely on embedding AI where reps already work, not asking them to go somewhere new.

Frequently Asked Questions
What types of sales data are most valuable for training AI?
CRM deal records with outcome labels, sales call transcripts tagged by stage and objection type, win/loss analysis notes, and product documentation are the highest-value data types. Labeled, outcome-linked data consistently delivers more value than raw volume.
Do I need a technical team or data scientists to train AI on my sales data?
Full fine-tuning requires ML expertise, but RAG-based implementations and purpose-built sales AI platforms can be configured by sales ops or enablement teams with standard integrations and minimal coding. Most platforms offer pre-built connectors for major CRM and call intelligence tools.
What is the difference between RAG and fine-tuning for sales AI?
RAG retrieves relevant sales knowledge at query time, fast, updatable, and lower cost. Fine-tuning adjusts model parameters to internalize your sales style and decision patterns, making it better for behavioral coaching but more expensive and dependent on labeled examples. RAG keeps knowledge current; fine-tuning freezes it until you retrain.
How long does it take to see results after training AI on sales data?
RAG-based systems can show early results within 4–8 weeks of deployment. Behavioral improvements from fine-tuned coaching AI typically become measurable in rep performance over 2–3 sales cycles. 58% of respondents say their company typically moves from AI pilot to full production in less than a year.
How do I protect customer privacy when using sales data to train AI?
Start by anonymizing or redacting PII from CRM records and call transcripts before training. Then apply these safeguards:
- Confirm your AI vendor's data governance and retention policies
- Use contractual carve-outs to restrict what the vendor can train on
- Avoid feeding legally restricted data (financial or health records) into external models
Can smaller sales teams train AI on their data, or is this only for enterprises?
RAG and pre-built AI sales platforms have lowered the barrier significantly, teams with as few as 5–10 reps and 6 months of CRM and call data can get meaningful results. 91% of SMBs using AI report a boost in revenue, and growing businesses are nearly twice as likely to invest in AI. Purpose-built platforms don't require building data infrastructure from scratch, making AI accessible to smaller teams.


