
Introduction
Sales managers face an impossible math problem: with dozens of reps conducting hundreds of calls weekly, manually reviewing each conversation for coaching simply isn't feasible. The result? Less than 1% of all sales calls are ever reviewed by managers, according to Avoma's 2025 research.
This coverage gap leads to inconsistent feedback, subjective assessments based on gut instinct rather than data, and reps who plateau without understanding exactly what behaviors need improvement.
An AI sales coaching scorecard solves this structural problem by introducing a repeatable, objective framework that evaluates every call against defined criteria. When AI powers the scoring, it happens automatically across 100% of conversations, turning coaching from a reactive, sporadic activity into a consistent, data-driven system.
Instead of guessing which calls to review or delivering memory-based feedback weeks after the fact, managers see exactly where each rep excels and where focused coaching produces results.
Key Takeaways
- AI sales coaching scorecards eliminate subjective feedback by measuring every call against standardized criteria like discovery rigor, objection handling, and closing effectiveness
- Automated AI scoring evaluates 100% of conversations versus the 1-9% coverage typical with manual review, freeing managers from manual review entirely
- Scorecard data becomes a coaching roadmap that identifies skill gaps, assigns targeted training, and tracks rep improvement over time
- Platforms like Pifini.ai close the loop by automatically routing reps into relevant training modules when call scores reveal specific performance gaps
What Is an AI Sales Coaching Scorecard and Why Does It Matter?
An AI sales coaching scorecard is a structured evaluation framework that measures rep behavior on customer calls against weighted criteria, with AI analyzing call transcripts or recordings to automatically assign scores. This eliminates the subjective, memory-based feedback that creates inconsistency across teams and prevents reps from receiving clear, actionable guidance on exactly what to improve.
The core problem scorecard-based coaching solves is simple: without a standard definition of what "good" looks like on a sales call, managers coach from instinct. One leader values relationship-building and penalizes reps for asking too many qualifying questions early. Another prizes efficiency and criticizes reps who spend time on rapport before discovery. Reps caught between these conflicting standards receive different feedback from different managers, creating performance inconsistency that directly impacts win rates.
Traditional manual review covers just 5-10% of calls due to time constraints, managers simply cannot listen to dozens of hour-long conversations weekly while also running pipeline reviews, forecasting, and handling escalations. AI-automated scoring evaluates 100% of conversations instantly, applying the same criteria with perfect consistency. When coverage jumps from under 10% to 100%, managers gain visibility into patterns that spot-checking never surfaces, like an entire team struggling with urgency creation in closing, or top performers consistently asking follow-up questions that average reps skip.
Structure directly impacts outcomes. CSO Insights research shows what happens when coaching moves from ad hoc to systematic:
- Formal coaching programs improve win rates by 11.5%
- Dynamic coaching tailored to individual needs boosts win rates by 27.9%
- Strong coaching cultures sustain win rates 16.7% higher than competitors
- Teams with structured coaching frameworks are 29% more likely to hit quota

Standardized evaluation criteria aren't just a management convenience, they translate directly to revenue.
That impact compounds when scorecards are built for specific roles. An AI scorecard configured for SDRs evaluates cold outreach skills; one built for AEs focuses on qualification and deal progression; a CSM version targets renewal and expansion conversations. Every rep type gets coaching tied to their actual job responsibilities, measured against the behaviors that drive their specific outcomes.
What to Include in Your Sales Coaching Scorecard: Key Dimensions to Score
Opening and Rapport
Strong call openings establish credibility, set a clear agenda, and create a comfortable tone in the first 60-90 seconds. Scorecards should evaluate whether the rep introduced themselves and their company clearly, confirmed the meeting purpose, outlined what would be covered, and set expectations for timing and next steps.
Exceeds expectations: Rep personalizes the opening with research about the prospect's company, references a specific trigger event or pain point, and secures explicit agreement on the agenda before proceeding.
Meets expectations: Rep delivers a clear introduction, states the purpose, and confirms the prospect has time for the conversation.
Falls below expectations: Rep jumps directly into pitch mode without context, fails to confirm availability, or creates confusion about why the call is happening.
First impressions set the psychological frame for everything that follows. A rushed, unclear opening signals inexperience and erodes trust before discovery even begins.
Discovery and Qualification
Discovery quality hinges on whether the rep asked meaningful questions to uncover the buyer's situation, pain, urgency, and decision criteria, aligned to proven frameworks like MEDDIC, BANT, or SPIN. MEDDIC adoption correlates with a 311% increase in win rates when fully utilized, while teams using structured methodologies are 437% more likely to complete qualification criteria.
To turn methodology elements into scoreable questions:
- BANT scorecard criteria: Did the rep confirm budget availability and range? Did they identify the decision-maker and their approval process? Did they validate the business need with specific pain examples? Did they establish a concrete timeline with milestone dates?
- MEDDIC scorecard criteria: Did the rep quantify the impact using metrics? Did they identify the economic buyer by name? Did they uncover decision criteria the buyer will use to evaluate solutions? Did they map out the decision process stages? Did they confirm pain points with business consequences? Did they identify a champion willing to advocate internally?
- SPIN scorecard criteria: Did the rep ask situation questions to understand context? Did they probe problems the buyer faces? Did they explore implications of leaving the problem unsolved? Did they guide the buyer to articulate the value of solving it (need-payoff)?

Score based on both breadth (how many required elements were covered) and depth (whether follow-up questions uncovered specific, actionable details rather than surface-level responses).
Objection Handling
Strong objection handling requires the rep to acknowledge the concern without dismissing it and respond with both empathy and logic. The resolution should tie directly back to the buyer's stated priorities, moving the conversation forward rather than deflecting, pushing through resistance, or accepting the objection as a dead end.
Effective objection handling follows a four-step pattern:
- Acknowledge: "I understand budget constraints are tight right now, and that's a real concern."
- Validate with empathy: "Many of our customers faced the same question when evaluating this investment."
- Reframe using buyer priorities: "You mentioned reducing churn by 15% was critical this year, let's look at how the ROI breaks down against that goal specifically."
- Confirm resolution: "Does that address your concern, or is there another aspect we should discuss?"
Weak objection handling sounds like: "That's not really an issue because our platform is very affordable," or worse, immediate capitulation: "I understand, let me know if things change."
Talk-to-Listen Ratio and Conversational Balance
AI measures conversational dynamics including talk time percentage, longest monologue duration, and follow-up question frequency. Gong Labs' 2026 analysis found that reps who closed deals talked 57% of the time versus 62% for reps who lost deals. Sales discovery calls work best with a 35:65 agent-to-customer ratio, per Voiso's 2026 benchmarks.
Optimal ratios vary by call type:
- Discovery calls: 35-40% rep talk time (prospect should dominate)
- Demo calls: 50-55% rep talk time (balanced explanation and interaction)
- Closing calls: 45-50% rep talk time (collaborative decision-making)
AI also tracks longest monologue length, lost deals feature extended seller monologues where reps lecture rather than converse. Interestingly, reps who won deals asked 15-16 questions per call, while reps who lost asked around 20 questions, suggesting quality matters more than quantity. Scorecards should penalize both extremes: reps who dominate conversations and reps who pepper prospects with rapid-fire questions without letting answers breathe.

Closing and Next Step Commitment
The closing dimension measures whether the rep articulated differentiated value, created appropriate urgency without pressure tactics, and secured a specific, calendar-confirmed next step with named attendees and a defined purpose, not vague endings like "I'll send over some information and we can reconnect next week."
Use this comparison to score closing quality:
| Strong Closing Behaviors | Weak Closing Behaviors |
|---|---|
| Summarized pain points from discovery | Generic value statements disconnected from the buyer |
| Connected solution capabilities to specific pains | Manufactured urgency ("This pricing expires Friday") unrelated to business drivers |
| Addressed remaining concerns explicitly | Passive endings that place follow-up responsibility on the prospect |
| Proposed a next action with business justification | Accepted "let me think about it" without any exploration |
| Confirmed date, time, and participants before ending | No defined next step agreed before hanging up |
For regulated industries, add compliance criteria: Did the rep include required disclosures? Did they avoid prohibited claims? Did they document consent where required? Skipping these steps in financial services, healthcare, or insurance can expose the business to audit findings, so they belong on the scorecard alongside performance metrics.
How to Build Your AI Sales Coaching Scorecard: A Step-by-Step Process
Defining Role Profiles and What "Excellent" Looks Like
Before scoring anything, document the ideal behavior model for each role. What does a top-quartile SDR discovery call sound like compared to an average one? This requires defining expected behaviors, not just outcomes, for each scorecard dimension and rating level.
For example, objection handling criteria should specify:
- Exceeds (4 points): Acknowledges objection, validates with empathy, reframes using prospect's stated priorities, confirms resolution, and advances conversation
- Meets (3 points): Acknowledges objection, provides logical response, confirms understanding
- Approaching (2 points): Responds to objection but doesn't validate or connect to priorities
- Below (1 point): Dismisses objection, becomes defensive, or accepts it without attempting resolution
Without this behavioral clarity, evaluators calibrate inconsistently and reps don't understand exactly what they're being measured against.
Selecting Your Methodology Alignment and Weighting Criteria
Choose a qualification framework that matches your sales motion: MEDDIC for enterprise deals with long cycles, BANT for transactional sales, SPIN for consultative selling. Map framework elements to specific scorecard questions that AI can detect in transcripts.
Assign weights to each dimension based on business priorities and what actually drives conversions. If your team consistently loses deals in the final stage because reps don't secure clear next steps, weight closing criteria higher (25-30% of total score). If discovery gaps cause deals to stall mid-pipeline, weight qualification rigor higher.
Sample weighting structure:
- Opening and rapport: 10%
- Discovery and qualification: 35%
- Objection handling: 20%
- Talk-to-listen ratio: 15%
- Closing and next steps: 20%
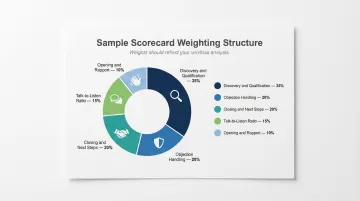
Weights should reflect reality, not what sounds rigorous. If your win rate analysis shows talk-to-listen ratio has minimal correlation with closed deals but qualification depth is the primary differentiator between wins and losses, weight accordingly.
Piloting, Calibrating, and Refining Before Full Rollout
Test the scorecard with one team for 4-6 weeks. Have multiple managers score the same five calls independently, then compare results to identify calibration gaps. If Manager A scores a call's objection handling as "Exceeds" while Manager B scores it "Approaching," the criteria language is too vague.
Aim for 80% inter-rater agreement as your baseline standard. Adjust criteria definitions wherever evaluators score identical behaviors differently. An uncalibrated scorecard creates the same subjectivity problem it was designed to solve: it just wraps that subjectivity in a false veneer of objectivity.
Rolling Out to the Team and Building a Coaching Cadence Around Scores
Introduce the scorecard transparently. Reps should understand every dimension, see example calls at each rating level, and know exactly what "Exceeds" versus "Meets" looks like before any of their calls are evaluated. Surprise scorecards breed resentment and defensiveness.
Structure coaching sessions around scorecard data using these principles:
- Lead with strengths before addressing gaps
- Focus on one or two high-impact improvement areas per session, not every low score
- Prioritize the dimension with the highest revenue impact when multiple gaps exist
- Tie improvement targets to specific call examples from the rep's own transcripts
A rep facing three weak dimensions won't fix all three at once. Pick the gap that matters most to pipeline and start there.
Establish a weekly or biweekly cadence for reviewing individual scores. Reps who receive weekly coaching hit 107% of quota versus 85% for those who don't, per CSO Insights. Frequency matters: weekly coached reps hit quota at 76%, monthly drops to 56%, and quarterly falls to 47%.
How AI Automates and Enhances Call Scoring at Scale
AI-powered platforms analyze call recordings or transcripts to automatically detect whether specific scorecard criteria were met. For example, the AI identifies whether the rep asked a qualifying question about decision timeline (by detecting phrases like "when are you looking to have this implemented?" or "what's driving the timing on your end?"), or whether an objection was acknowledged before a response was offered (by analyzing conversational patterns where the rep paraphrases the concern before countering it).
This removes the manager bottleneck from the scoring process. According to AskElephant's 2026 analysis, managers save 10+ hours weekly when scorecards replace manual call review. Automated QA changes the equation from scoring 5-10% of interactions to evaluating up to 100% across multiple channels, per SQM Group's research.
AI surfaces supporting evidence for each score by pointing managers directly to the timestamp where criteria were or weren't met. Instead of forcing managers to listen to a 45-minute call to verify a score, the platform shows: "Objection handling scored 'Approaching', objection raised at 18:32, rep responded at 18:41 without acknowledgment." Coaching conversations move faster when the evidence is already extracted and organized, managers arrive with specifics, not impressions.
That timestamp-level precision enables three concrete outcomes:
- Faster debriefs, managers reference exact moments rather than reconstructing calls from memory
- More specific feedback, reps hear "you skipped acknowledgment at 18:41" instead of "work on objection handling"
- Higher coaching accountability, both parties can review the same clip, reducing score disputes
Scoring at this level of detail also enables the next step: automated remediation. Platforms like Pifini extend AI scoring beyond evaluation, after identifying a performance gap, say a rep consistently scoring below expectations on qualification rigor, the AI automatically flags the skill deficit and routes the rep into targeted training modules covering discovery frameworks and question techniques.
This creates a closed loop between what was scored on a live call and what learning intervention fires next, eliminating the manual admin work of assigning training based on performance data. Pifini's training impact analysis then connects those coaching actions back to actual deal outcomes, so managers can show whether reps who completed objection handling training improved win rates or shortened deal cycles, not just whether they finished a module.
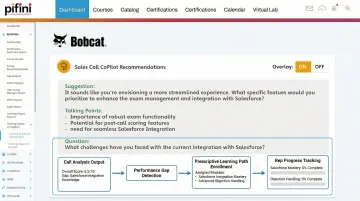
Turning Scorecard Data into Coaching Action and Measurable Rep Growth
Use aggregate scorecard data across the team to distinguish systemic gaps from individual weaknesses. If 70% of reps score below expectations on securing next steps, that's a training program issue, the team hasn't been taught a consistent methodology for closing calls with commitment. If one rep consistently struggles with objection handling while others don't, that's a targeted 1:1 coaching issue requiring role-play practice and shadowing top performers.
This distinction changes the coaching response entirely. Systemic gaps require curriculum development, group workshops, or revised playbooks. Individual gaps require personalized coaching plans, skill-specific training assignments, and pairing struggling reps with mentors who excel in that dimension.
Connect scorecard performance trends to pipeline outcomes by correlating which reps score highest on qualification rigor with deal velocity, average deal size, and win rate. When coaching time increased from under 30 minutes to over 2 hours weekly, win rates rose from 43% to 56%, per Revegy research.
Gartner's Corporate Executive Board found a 19% revenue boost from effective sales coaching. That's where coaching stops being a "soft" activity measured by completion rates and becomes a revenue lever measured by closed deals and contract value.
Build a rep development tracking system by monitoring score trajectories over time, not just snapshot scores. Track which reps are improving, plateauing, or regressing after coaching interventions. A rep whose discovery scores climbed from 2.1 to 3.4 over eight weeks demonstrates coaching effectiveness; a rep stuck at 2.3 for three months signals the intervention isn't working and a different approach is needed.
This longitudinal data turns scorecard history into a management tool with three direct applications:
- Performance reviews: Replace subjective impressions with objective skill development trends
- Promotion decisions: Reps improving consistently across dimensions outperform those with static high scores who've plateaued
- Retention signals: Surface struggle patterns early enough to intervene before a rep churns
Common Scorecard Mistakes That Undermine Coaching Effectiveness
The most common pitfall is building a scorecard that measures too many things at once or includes criteria that don't correlate with deal outcomes. A 15-dimension scorecard measuring everything from "energy and enthusiasm" to "use of prospect's name" results in reps and managers spending time on dimensions that don't move the needle.
Start with 5-7 high-impact criteria directly tied to your win/loss analysis. If your best deals share a pattern, reps who uncover multiple stakeholders early or reps who quantify pain with specific metrics, those behaviors belong on your scorecard. If a dimension doesn't correlate with actual closed business, prune it. Validate which dimensions predict outcomes, then focus coaching energy there.
Three failure modes consistently derail even well-intentioned scorecards:
- Over-measurement: Too many dimensions dilute focus and waste coaching time on behaviors that don't affect win rates
- Calibration failure: Vague criteria let managers score the same behavior differently, producing unreliable data reps don't trust
- Disconnected scoring: Call scores that don't trigger specific training actions turn the scorecard into a report card, not a coaching tool

Calibration failure is especially damaging. One manager interprets "strong objection handling" as any response that doesn't concede; another requires the rep to tie back to the buyer's priorities. That gap produces false performance data, and reps quickly lose trust in a system that feels arbitrary.
An uncalibrated scorecard is often worse than no scorecard. It creates false confidence in data that doesn't reflect reality, so leaders make coaching assignments, PIPs, and promotion decisions based on scores that aren't measuring what they think they are.
The third failure mode is scoring calls without connecting results to training. If scorecard output is just a number reviewed in quarterly business reviews, it's a report card, not a coaching tool. The value lives in the closed loop: low score on objection handling → automatic enrollment in a targeted training module → tracked improvement in subsequent call scores → measurable impact on win rate. Without that connection, the entire system collapses into administrative overhead.
Frequently Asked Questions
What should be included in an AI sales coaching scorecard?
Core dimensions include opening and discovery quality, qualification framework adherence (MEDDIC, BANT, or SPIN), objection handling effectiveness, talk-to-listen ratio, and closing with next-step commitment. Each dimension should be weighted based on what most directly drives conversions for that specific role, SDR scorecards emphasize different behaviors than AE or CSM scorecards.
How does AI score sales calls automatically?
AI analyzes call transcripts or recordings using natural language processing to detect whether specific behavioral criteria were met, for example, whether a rep asked qualifying questions about budget or acknowledged objections before responding. The system assigns scores from predefined rubrics and surfaces timestamped evidence showing exactly where criteria were or weren't satisfied, removing the need for managers to manually review each call.
How often should sales coaching scorecards be reviewed and updated?
Individual rep scores should be reviewed weekly or biweekly in 1:1 coaching sessions to maintain momentum and ensure timely feedback. The scorecard framework itself should be audited quarterly to confirm that weighted dimensions still correlate with current business outcomes, sales methodology, and market conditions, what drove wins six months ago may not predict success today.
Can sales coaching scorecards be used for channel partner and reseller teams?
Yes, scorecards can be configured for partner sales teams with criteria adapted to the partner selling context, such as product knowledge depth, partner-specific objections, deal registration behaviors, and co-selling protocols. This enables consistent coaching standards across distributed indirect sales ecosystems where partners may receive less direct oversight than internal teams.
What is the difference between a manual scorecard and an AI-powered scorecard?
Manual scorecards cap coverage at roughly 5-10% of calls, limited by manager bandwidth and prone to inconsistency depending on which calls get selected. AI-powered scorecards evaluate 100% of conversations against consistent criteria instantly, freeing managers to focus on coaching rather than grading and ensuring no performance gaps go undetected.
How do you connect scorecard results to rep training and development?
Scorecard gaps should map directly to specific training modules, ideally in a platform that auto-routes reps into relevant content when scores drop below a defined threshold. Pifini.ai's prescriptive learning system does exactly this, detecting low scores on discovery or objection handling, then auto-enrolling reps into targeted training paths that address those specific deficits rather than waiting for a manager to schedule a session.


