
Introduction
Traditional manual review processes can only evaluate 1–5% of total call interactions, leaving 95% of customer conversations unscored, uncoached, and untracked. That coverage gap compounds fast. Without visibility into the majority of calls, organizations miss winning behaviors, let compliance violations slip, and lose coaching windows that directly affect revenue.
Choosing the right call quality approach isn't just an operational decision, it directly affects agent performance, coaching consistency, compliance risk management, and revenue outcomes. This comparison breaks down the tradeoffs between automated call scoring and manual review, helping revenue leaders make informed decisions based on team size, call complexity, and coaching goals.
Key Takeaways
- Manual review offers rich qualitative insight but covers only 1–5% of calls, creating blind spots
- Automated scoring evaluates 100% of calls with consistent criteria, delivering speed and scale
- Manual review wins on nuanced, high-stakes conversations; automated scoring wins on volume and consistency
- Automated systems drive data-driven coaching at a scale no human review team can match
- Top-performing organizations use hybrid models, automating coverage while reserving human review for depth
- Platforms that connect AI call scoring to targeted training close the loop between evaluation and measurable improvement
Automated Call Scoring vs Manual Call Quality Review: Quick Comparison
Here's how the two approaches compare across the metrics that matter most to sales and QA teams:
| Attribute | Manual Call Quality Review | Automated Call Scoring |
|---|---|---|
| Coverage | 1–5% of total call volume | 100% of interactions |
| Consistency | Varies by evaluator; prone to bias | Identical criteria applied uniformly |
| Speed | Days to weeks for feedback | Minutes to hours |
| Scalability | Costs scale linearly with headcount | Marginal cost approaches zero at scale |
| Cost at Scale | $5–$15 per evaluation (industry estimates) | Significantly lower per-call cost |
| Human Nuance | Detects tone, context, valid deviations | Can miss sarcasm, emotional context |
| Real-Time Feedback | Limited; delayed by review cycle | Near-instant results |
| Coaching Integration | Manual routing to training | Auto-enrollment based on gaps flagged |

This table provides a reference point, not a verdict. Context, team size, call complexity, regulatory requirements, determines the right fit. Each tradeoff carries different weight depending on your operation, the sections below unpack which factors should drive your decision.
What is Manual Call Quality Review?
Manual call quality review is a process where trained human evaluators listen to recorded or live calls and score them against structured rubrics covering criteria such as communication skills, script adherence, problem resolution, compliance, and empathy.
Strengths of Manual Review
Human reviewers bring irreplaceable value in specific contexts. Where automated systems score against fixed criteria, a trained evaluator reads between the lines:
- Detects emotional tone shifts that signal customer frustration before the situation escalates
- Interprets ambiguous situations where script adherence alone doesn't tell the full story
- Recognizes when an agent's deviation from protocol was actually warranted
- Surfaces qualitative insights, workflow gaps, knowledge deficits, that metric-driven systems miss
Core Limitations
Research indicates manual review typically covers only 1–5% of total call volume, creating sampling bias, reviewer inconsistency, and recency bias. According to SQM Group's 2025 analysis, that limited coverage leaves the vast majority of conversations unmonitored.
The consequence: compliance violations, coaching opportunities, and winning behaviors stay invisible, not because they don't exist, but because no one was listening.
Delayed feedback cycles further weaken coaching impact. By the time feedback reaches the agent, often days or weeks later, context has faded and behavior has already reinforced itself.
The Scalability Wall
Those feedback delays point to a deeper structural problem: cost. Manual review scales linearly with headcount, adding 1,000 calls means adding reviewers. For large or distributed teams, comprehensive coverage becomes both expensive and operationally impractical.
Use Cases for Manual Call Quality Review
Manual review delivers the most value in:
- Emotionally sensitive calls where reading tone and empathy matters more than script compliance
- Regulated industries (healthcare, financial services, legal) requiring a human sign-off for compliance verification
- New agent onboarding where personalized, in-person feedback builds confidence faster than automated scores
- Edge cases where an agent deviated from protocol for good reason and context determines whether it was right or wrong
What is Automated Call Scoring?
Automated call scoring is an AI-driven process that uses speech recognition, natural language processing (NLP), and machine learning to evaluate every call against custom scorecards.
The system analyzes calls across a range of factors:
- Script adherence and compliance phrase detection
- Sentiment shifts and objection handling
- Talk-to-listen ratio and keyword usage
- Silence/hold time and discovery questioning
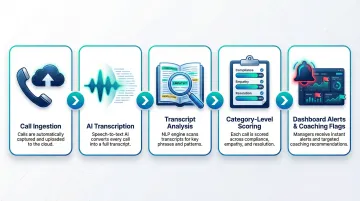
How It Works in Practice
- Calls are ingested from the telephony system
- AI transcribes the conversation
- The transcript is analyzed against predefined scoring criteria
- Each call receives category-level scores
- Results surface in dashboards with alerts and coaching flags, no human evaluator required per call
Core Advantages
Automated scoring delivers measurable advantages over manual review:
- 100% call coverage with no sampling blind spots
- Consistent application of identical criteria to every call
- Near-instant feedback turnaround
- Lower marginal cost per evaluation as volume scales
Transparent Limitations
Automated systems can misinterpret sarcasm, emotional context, or valid script deviations. Initial setup requires scorecard configuration and calibration. AI accuracy depends heavily on data quality and model maintenance. Purely metric-driven outputs can miss the qualitative insight coaches need for rich, personalized feedback.
Extended Value: Closing the Loop from Scoring to Learning
Those limitations aside, the more pressing gap in traditional scoring, manual or automated, is what happens after the score. Most tools stop at measurement.
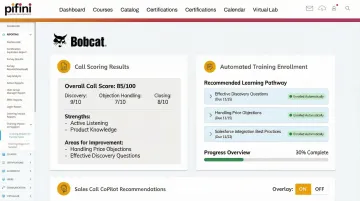
Pifini's AI call scoring addresses this directly: it evaluates every call, identifies specific skill gaps, such as weak objection handling or discovery questioning, and automatically routes sales reps or partners into targeted training modules. Scoring becomes the trigger for learning, not just a report card, with no manual follow-up required.
Use Cases for Automated Call Scoring
Automated scoring delivers the most value in:
- Large sales teams or contact centers with high daily call volumes where manual review can't scale
- Distributed or partner-channel organizations where in-person supervision isn't practical
- Compliance-sensitive environments that require 100% audit coverage to meet regulatory standards
- Teams running structured methodologies (MEDDIC, BANT, SPICED) that need consistent adherence tracking across every rep
Automated vs Manual: 6 Dimensions That Define the Difference
Coverage and Blind Spots
Manual review creates a statistically small, potentially unrepresentable sample. When only 1–5% of calls are reviewed, compliance violations, coaching opportunities, and winning behaviors in the unreviewed majority remain invisible.
For revenue teams, this matters acutely. The patterns that drive or kill deals, how reps handle pricing objections, position ROI, or navigate procurement processes, often appear across hundreds of calls, not a handful. Automated scoring eliminates this blind spot by evaluating every interaction, ensuring no deal-critical conversation goes unanalyzed.
Consistency and Evaluator Bias
Human reviewers bring expertise but also introduce variability. Different evaluators score the same call differently based on interpretation, fatigue, or personal standards. The COPC CX Standard 7.0 addresses this by requiring quarterly calibration to achieve inter-rater reliability above 85%.
Automated scoring applies identical criteria uniformly to every call, so agents know exactly what's being measured and trust that the same standard applies to everyone.
Speed and Feedback Loops
Manual review typically delivers feedback days or weeks after the call, by which point context has faded and behavior has already reinforced itself. Automated scoring delivers results within minutes to hours.
Coaching feedback tied closely to the actual interaction changes behavior more reliably than delayed review. The shorter the gap between call and coaching, the faster reps learn and the longer they retain it.
Scalability and Cost Economics
Manual QA costs scale linearly with headcount, adding calls means adding evaluators. Industry sources commonly cite $5–$15 per manual evaluation. Automated scoring's marginal cost approaches zero after initial setup, shifting the cost structure entirely for high-volume teams:
- Manual QA: cost grows with every call reviewed
- Automated scoring: fixed infrastructure cost, unlimited coverage
- Net result: dramatically lower cost-per-insight at scale
Depth of Human Insight
AI handles volume and consistency, human judgment handles nuance. Experienced reviewers read between the lines, recognize when a deviation from script was warranted, understand cultural or emotional context, and deliver the kind of nuanced coaching conversation that builds rep confidence and trust. Human reviewers remain superior here, which is why they remain essential in hybrid models.
Coaching and Training Integration
Scoring alone doesn't improve performance, what happens after the score determines impact. Automated systems that connect scoring to targeted learning create a development loop that compounds over time.
Pifini's platform flags performance gaps through call analysis and auto-enrolls reps into prescriptive learning pathways within its Enterprise LMS. When a rep consistently struggles with objection handling, the system routes them into targeted microlearning modules and AI roleplay simulations, turning a score into an action, and an action into measurable improvement.
Which Approach Should You Choose?
Which Approach Should You Choose?
Choose Manual Review When:
- Your team is small and call volume is manageable (under 200 calls per week)
- Calls involve high-stakes negotiations or emotionally sensitive situations requiring human judgment
- Operating in heavily regulated industries where human verification of compliance is required
- Building coaching relationships with early-stage reps where individual trust and context matter
Choose Automated Scoring When:
- Managing large or distributed teams, partner channels, or high call volumes where full coverage is operationally impossible manually
- You need consistent methodology adherence tracking across every rep
- Real-time or same-day feedback loops are critical to coaching velocity
- You need data-driven insights to identify systemic skill gaps and prioritize training investments
The Hybrid Recommendation
The most effective organizations use automated scoring as the operational backbone, ensuring 100% coverage, consistency, and speed, while reserving human review for complex calls, disputed scores, and personalized coaching conversations. Pifini is built around this model: AI call scoring handles full coverage and flags gaps, while automated training enrollment routes reps into targeted learning based on those scores, all within a single platform at $50/user/year, without adding headcount or administrative overhead.
Conclusion
Neither approach is universally superior. Manual review brings nuanced human judgment for complex, high-judgment situations, while automated scoring delivers the coverage, consistency, and speed modern revenue teams require at scale. The right choice depends on team size, call complexity, regulatory context, and coaching goals.
As sales teams grow more distributed and call volumes increase, the organizations that win will be those that build a system, not just a process, around call quality. Automated scoring gives you the data infrastructure to act at scale. Human reviewers supply the coaching depth that data alone can't replicate. When both feed into a connected enablement system, one that routes insights directly into training and rep development, call quality stops being a reporting exercise and starts driving real revenue outcomes.
Frequently Asked Questions
What is the difference between manual and automated call quality reviews?
Manual review relies on human evaluators scoring a small sample of calls for qualitative depth, while automated call scoring uses AI to evaluate 100% of calls consistently and at speed. Human review goes deeper on individual calls; automation covers every one.
What are the advantages of automated call scoring over manual call quality review?
Automated scoring delivers advantages that manual review can't match at volume:
- 100% call coverage with no sampling blind spots
- Consistent, unbiased scoring across all reps
- Near-instant feedback turnaround
- Lower marginal cost as call volume grows
- Pattern detection across the full conversation dataset
How can I improve call center quality scores?
Combine clearly defined scoring criteria, regular calibration sessions, faster feedback loops enabled by automation, and connect scoring data to targeted coaching and training, so scores reflect ongoing improvement rather than just measurement.
Can automated call scoring replace human reviewers entirely?
Automated scoring handles coverage and consistency at scale, but human reviewers remain valuable for complex interactions, nuanced coaching conversations, and disputed evaluations. The hybrid model is the recommended approach for most organizations.
What criteria does automated call scoring evaluate?
Most QA scorecards cover dimensions like:
- Script adherence and compliance phrase detection
- Sentiment and tone analysis
- Talk-to-listen ratio and silence/hold time
- Keyword usage and objection handling
Specific criteria are configured to match each organization's scorecard.
When should you still use manual call quality review?
Manual review is most valuable for complex or emotionally sensitive calls, high-stakes regulated interactions, personalized rep coaching sessions, and situations where AI may misinterpret valid context or script deviations.


